Scik-Learn之特征工程(二)
系统环境Ubuntu、Deepin
数据的特征预处理
特征处理:通过特定的统计方法(数学方法)将数据转换成算法要求的数据
sklearn特征处理API:sklearn.preprocessing
-
数值型数据:标准缩放:
-
1、归一化
- 2、标准化
- 3、缺失值
-
- 别型数据:one-hot编码
- 时间类型:时间的切分
归一化
特点:通过对原始数据进行变换把数据映射到(默认为[0,1])之间
公式:
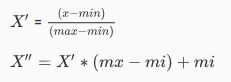
注:作用于每一列,max为一列的最大值,min为一列的最小值,那么X’’ 为最终结果,mx,mi分别为指定区间值默认mx为1,mi为0
归一化计算过程
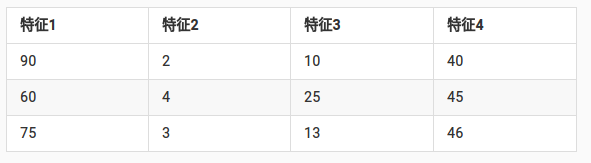
根据公式进行处理:
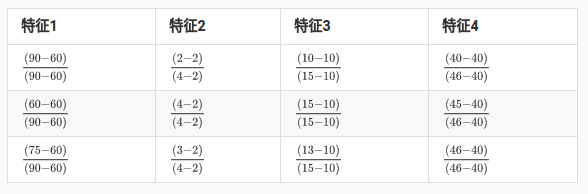
注:里面是第一步,还需要第二步乘以(1-0)+0
sklearn归一化API
sklearn.preprocessing.MinMaxScaler
MinMaxScaler语法
- MinMaxScalar(feature_range=(0,1)…)
- 每个特征缩放到给定范围(默认[0,1])
- MinMaxScalar.fit_transform(X)
- X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后的形状相同的array
案例测试
from sklearn.preprocessing import MinMaxScaler
mydata = [[90,2,10,40],
[60,4,15,45],
[75,3,13,46]]
# 创建归一化实例对象
unificati = MinMaxScaler()
# 转换为归一化特征数据
mydatas = unificati.fit_transform(mydata)
print('归一化特征数据:\n',mydatas)
运行结果:
[[1. 0. 0. 0. ]
[0. 1. 1. 0.83333333]
[0.5 0.5 0.6 1. ]]